
此前我们学习了如何为一体的文本配音的两种方法,下面我们将学习本次最为推荐的一种配音方法!
二、语音转换
方法三:声线模型+TTS(推荐)
简单介绍:根据角色人设训练出对应的声线模型,再使用AI配音网站将待替换的音频提取出来,使用语音转换软件,替换音频中的声线。
注意:语音转换软件配置要求
①一张支持 CUDA 的 nVIDIA 显卡,拥有至少 6G 以上显存
②Windows 10/11 系统
具体步骤:
1、训练声线模型
可查看以下教程:
如何获取新声线2、获取待替换的音频素材
具体步骤参考以下教程:
方法一:使用AI配音网站进行配音区别操作:
①在试配的时候不用过多考虑声线是否贴合角色,更着重于考虑说话方式是否符合你心中想要的效果。
这里也需要注意在挑选TTS时,一般情况下不使用异性的TTS,否则效果就会变得男女莫测。
举例:
女性角色+男性TTS
男性角色+女性TTS
②暂时不进行音频文件格式(.wav)到(.mp3)的转换。
3、声线替换操作
(1)下载安装语音转换软件:So-VITS-SVC 4.1;网上有非常多的安装使用教程,可以自行搜索学习。
原作者教程:
点击查看原作者视频教程参考推荐:
AI声音克隆——so-vits-svc完全教程(2)打开So-VITS-SVC 4.0的WebUI页面
按照以下步骤操作:
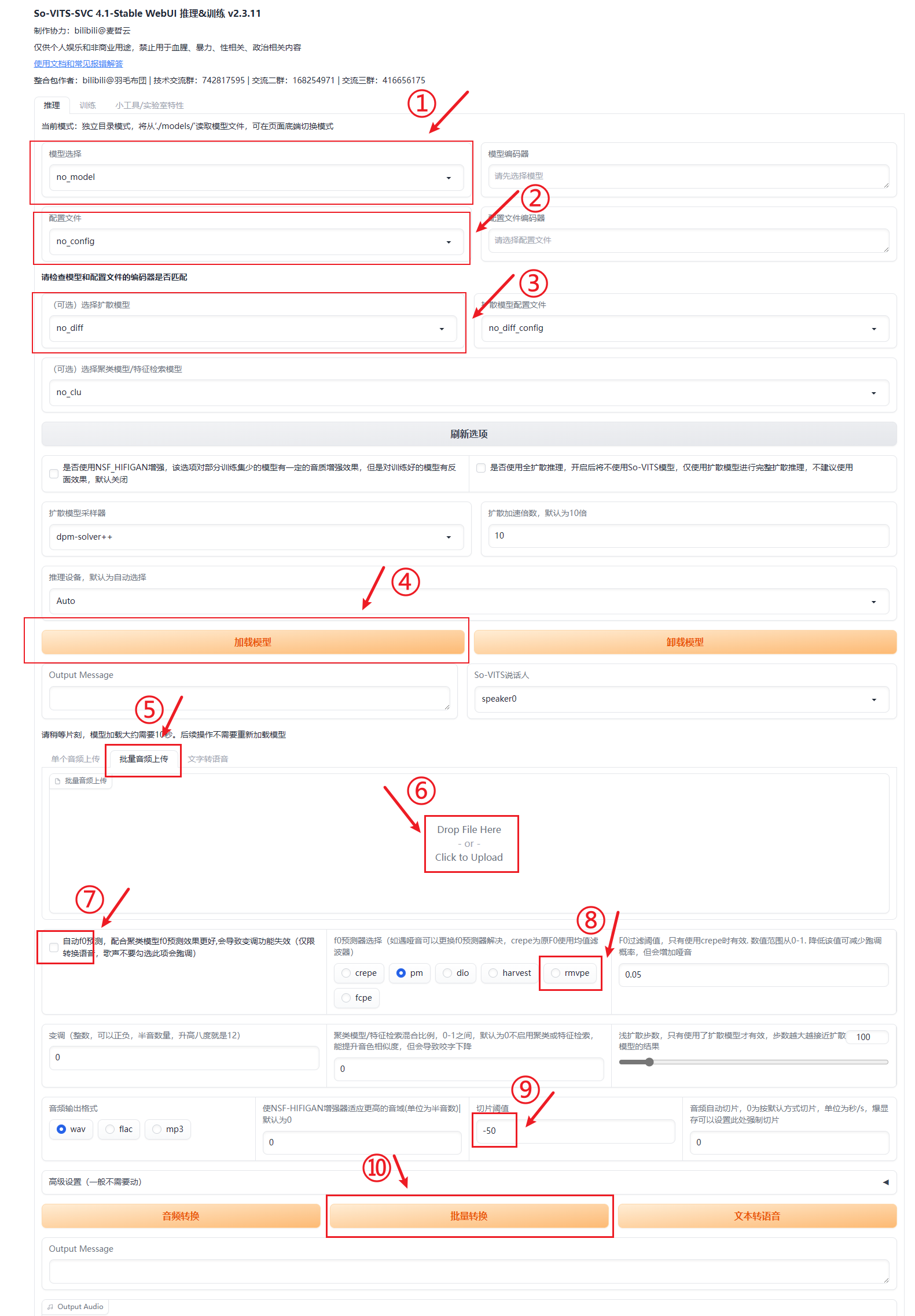
①选择训练好的声线模型(xx.pth)
②选择对应的配置文件(xx.json)
举例:

③选择对应的扩散模型(xx.pt),软件会自动抓取扩散模型的配置文件(xx.yaml),注意一定要保证文件名称一致;没有训练扩散模型的,可以不用选择。
④点击加载模型,加载完成会出现以下信息:

⑤点击切换到【批量音频上传】。
⑥点击空白框,上传第二步处理好的待替换的音频素材,如下:

⑦点击开启【自动f0预测】。
⑧点击切换到【rmvpe】。
⑨将切片阈值改为-60。
⑩点击【批量转换】,进行声线替换。完成后如下:

⑪打开文件夹(参考路径:F:\so-vits-svc\so-vits-svc\results)
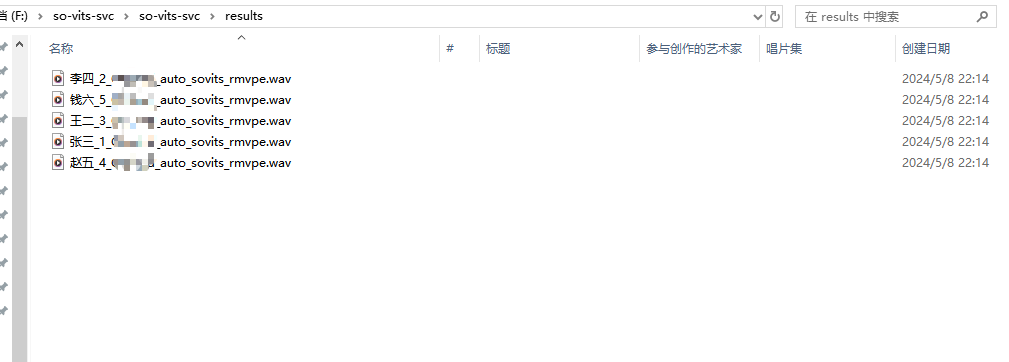
试听:
转换前:
转换后:
不同声线模型效果(依次使用了青年、儿童、老年声线模型):
将所有的待替换音频都处理完毕,就可以开始最后的操作了!
后续的操作请查看教程:
如何将配音音频导入橙光工程