
本篇教程将会为大家详细讲解如何从零获取新声线,包括以下步骤:0)下载安装语音转换软件:So-VITS-SVC 4.1
1)准备原始音源;
2)音源处理;
3)音源预训练;
4)扩散模型训练;
5)主体模型训练;
6)整理归档。
还会为大家带来使用使用So-VITS-SVC的【静态声线融合】功能组合声线的方法。
一、从零开始训练模型
0、下载安装语音转换软件:So-VITS-SVC 4.1
点击下方链接可查看原作者教程:
无需配置环境的本地训练/推理教程整合包下载和使用指南:
So-VITS-SVC1、准备原始音源
如果是从零开始的音源(如从电视剧、听书、游戏中获取),使用音频软件将背景音乐分离,获得干净的人声片段即可。这个过程非常繁琐耗时,且音频质量与最终训练的效果直接正相关。(有侵权风险,请谨慎使用!)
2、音源处理
将原始音源命名为1.wav-10.wav(路径、文件名不要有中文和空格之类的),使用之前所推荐的切片工具Slicer-gui,将原始音源所在的文件夹下所有文件进行切割,输出到一个新建文件夹。这个新建的文件夹建议以说话人的名字命名(如Noelle)。
切片工具指路:
点击跳转切片工具链接3、音源预训练
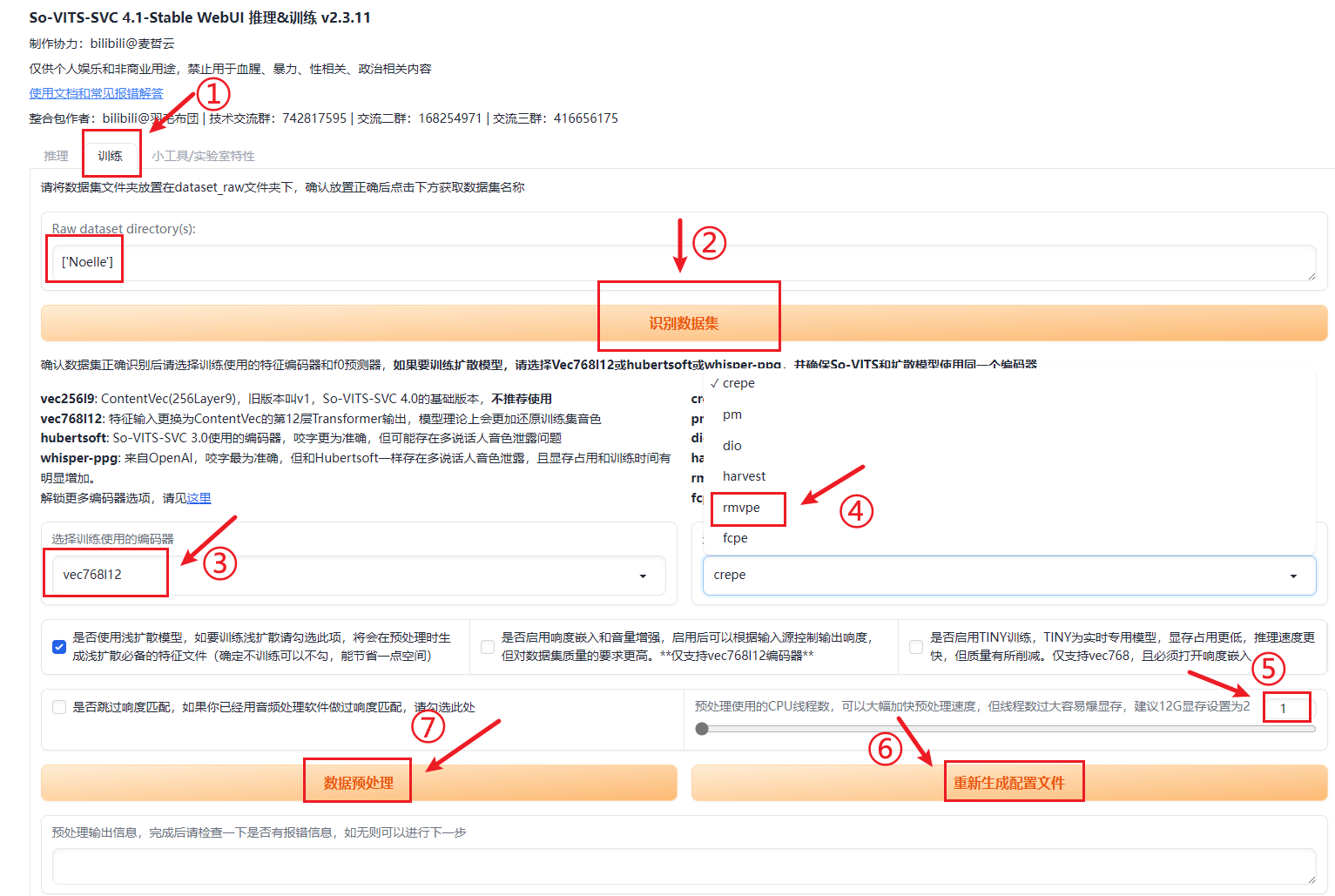
将切好一大堆小wav的文件夹(如Noelle),剪切到dataset_raw文件夹下(如:sovits/dataset_raw/Noelle)。在“训练”标签下,点击识别数据集,如果能正确找到文件夹,就可以设置参数进行预训练。
参数:编码器:vce768|12,f0预测器:rmvpe,勾选使用浅扩散模型,线程数量设置为2(显存小于12G的建议就设置为1)。
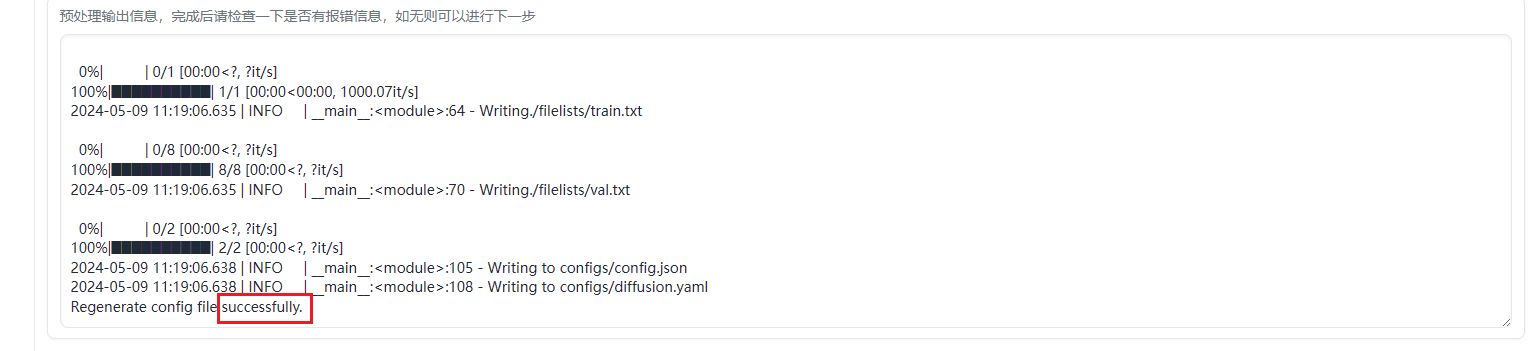
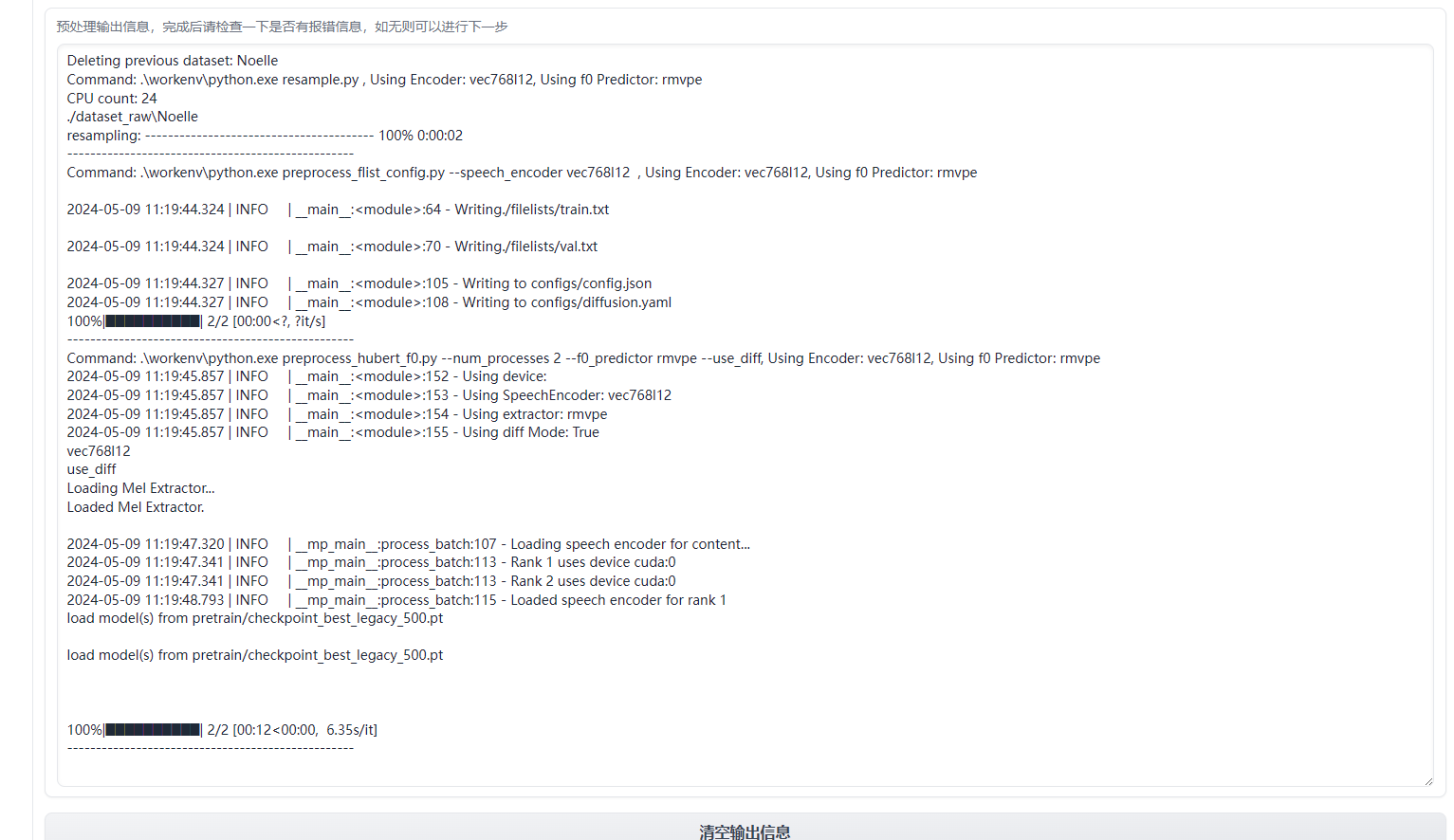
参数设置好后,先点击“重新生成配置文件”,再点击“数据预处理”。如无问题,就会开始进行预处理,时间大约在20分钟左右。
4、扩散模型训练
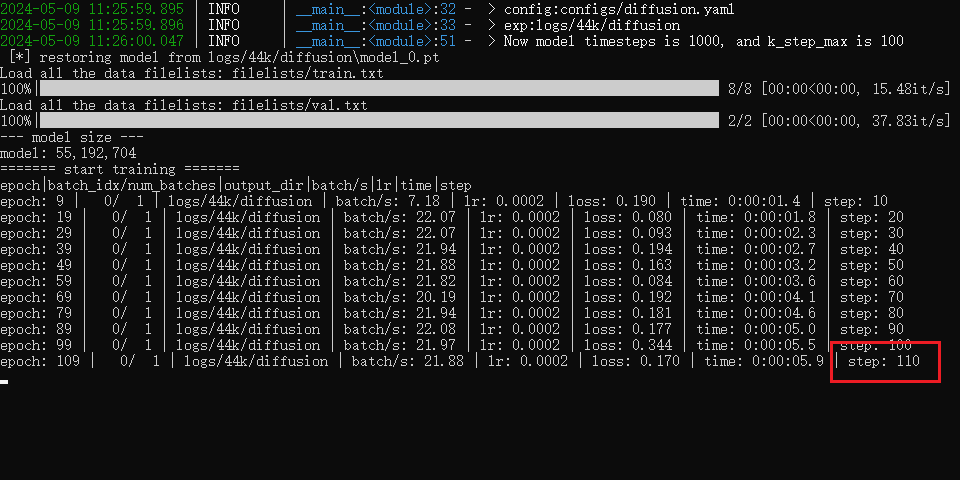
预处理结束后,建议先训练扩散模型(因为速度比较快)。在扩散模型配置部分设置好参数(勾选只训练100步,调整为每1000步保存一次,其他不用改),点击“从头训练扩散模型”,就会开始训练。
这个训练窗口不会自动停止,观察训练了2000步(即step:2000)以上后,直接关闭即可。
5、主体模型训练
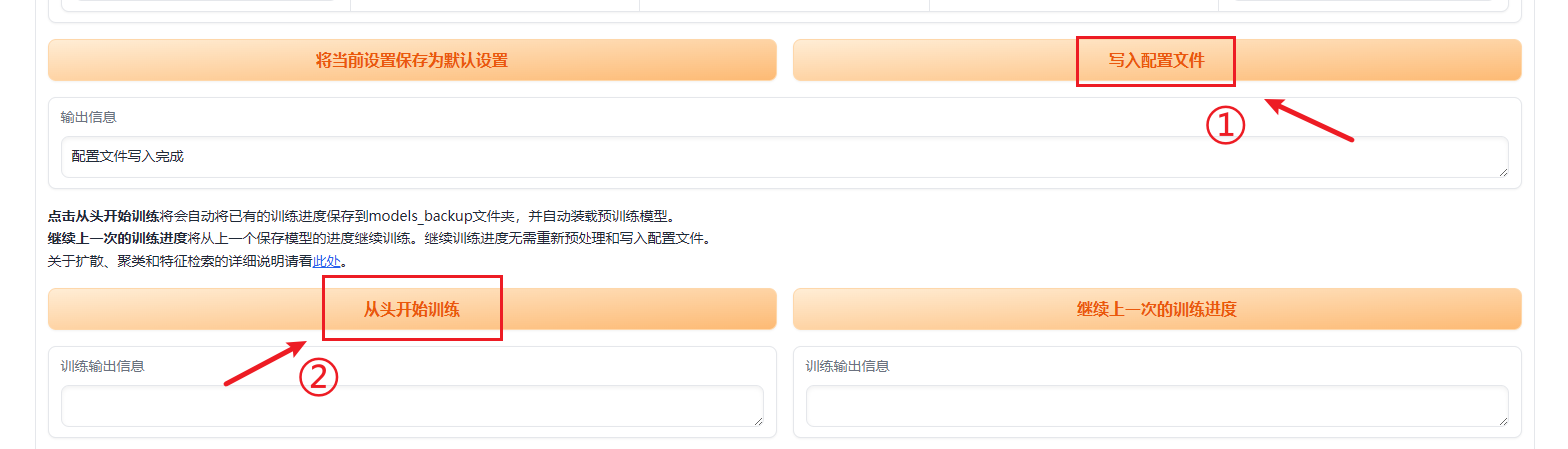
设置主题训练的参数:每隔1000步保存一次模型;加载所有数据集到内存中。点击“写入配置文件”,最后点击“从头开始训练”就可以开始训练了。
这个训练窗口不会自动停止,建议训练8000步以上再关闭。根据经验,训练时间越久越好,挂一晚上也是可以的。最低不建议低于8000步。训练觉得差不多了关闭训练窗口即可。
开始训练后的页面:
训练到200步时,会自动保存一次日志:
6、整理归档
在sovits/logs/44k/文件夹下可以找到训练的成果。G_数字.pth,就是训练结果的主模型,比如8000步就是G_8000.pth;config.json是配置文件;diffusion文件夹下的.pt文件(如model_2000.pt)是扩散模型,config.ymal是扩散模型的配置文件。把这4个文件重命名,存到自己的文件夹,就算完成了训练。
当需要使用的时候,把这些文件放到models文件夹下的正确位置(.pt格式的文件需要放在models/diffusion文件夹下,其他三个文件放在models文件夹下)
二、组合声线
另有一个灰色的小方法,就是使用So-VITS-SVC的【静态声线融合】功能,将2~4个声线模型组合起来,这样就可以得到差异化的声线模型。具体步骤如下:
①双击桌面文件Sovits 4.1 WebUI,会在浏览器中打开Gradio页面。
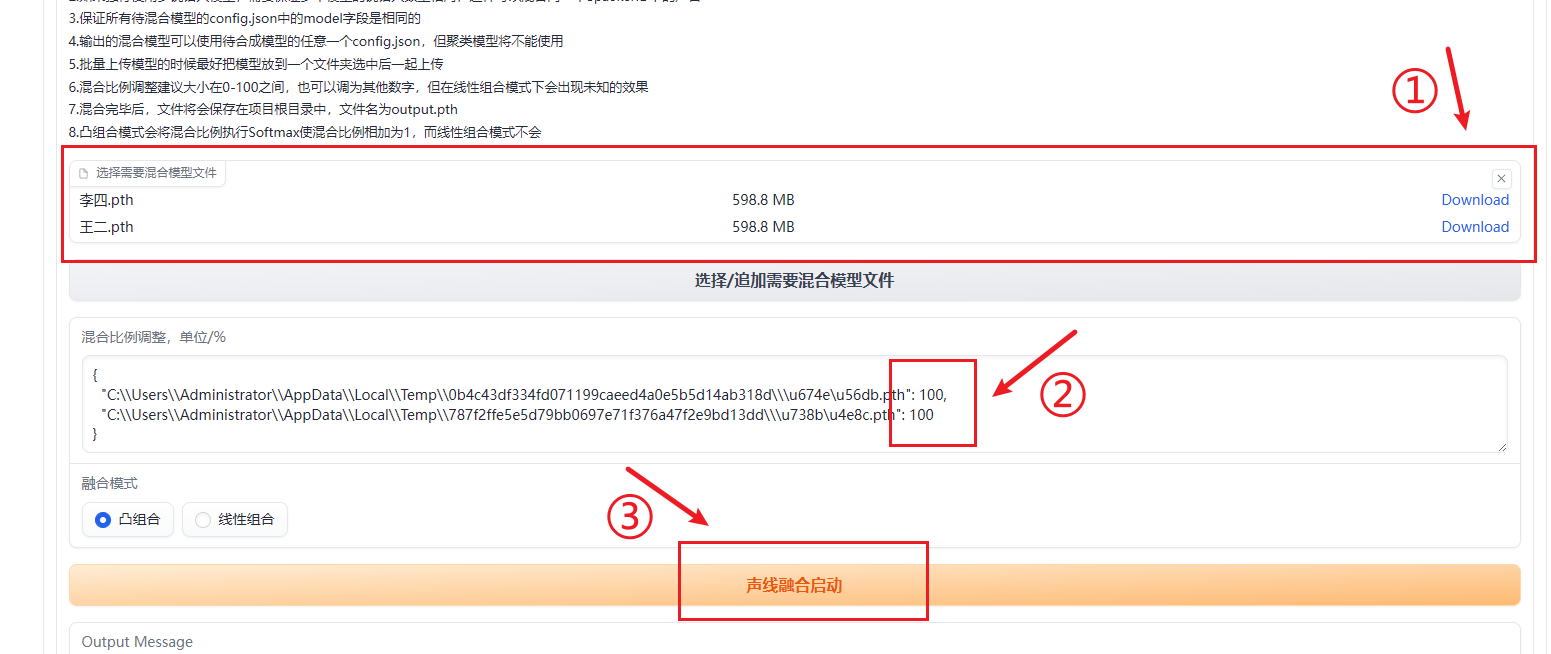
②选择“小工具/实验室特性”,点击“选择需要混合模型文件”区域,会弹出文件夹,找到so-vits-svc文件夹下models文件夹,在里面选择你要混合的模型文件(xx.pth)。
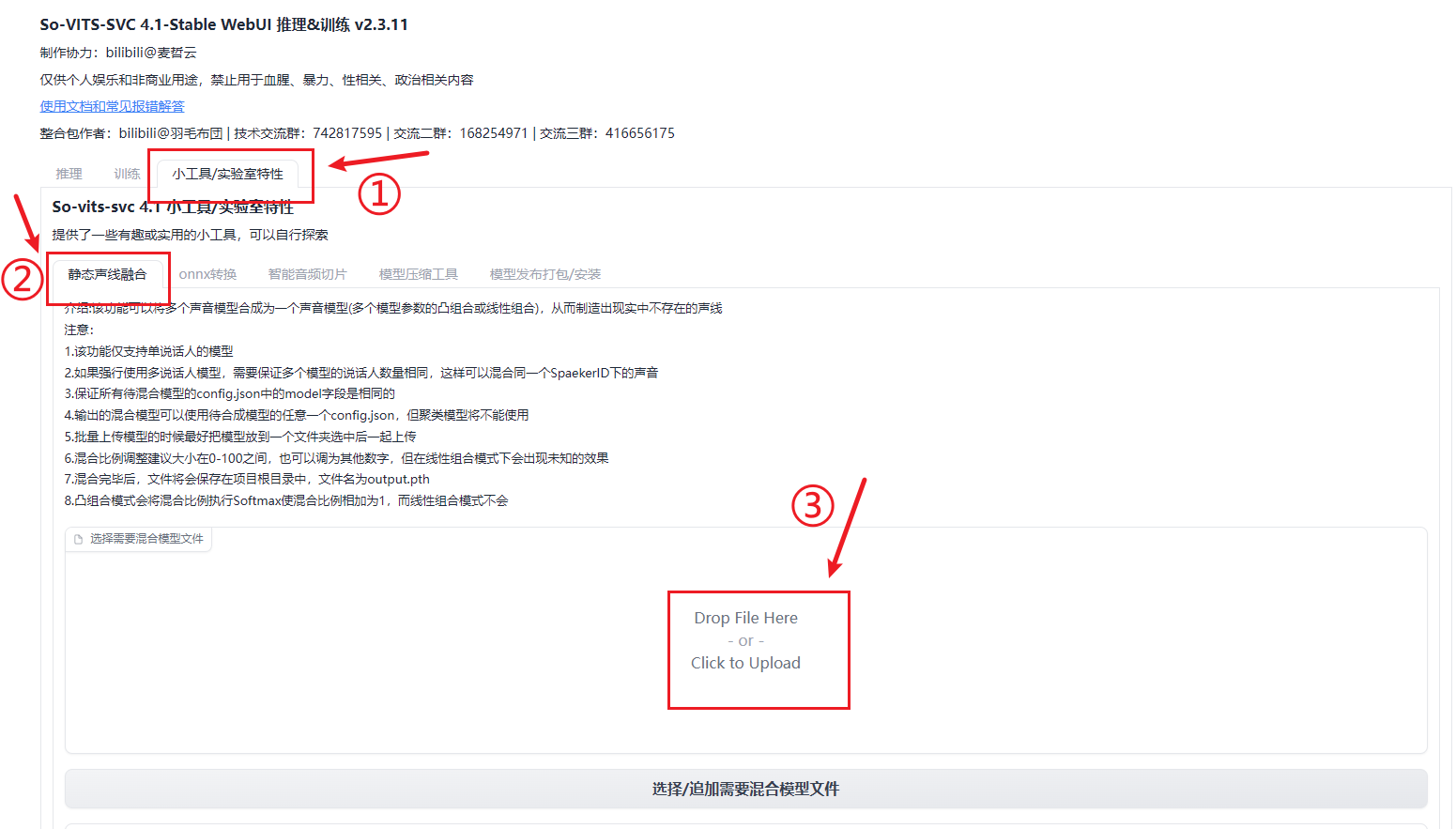
③待混合的模型加载完毕后,在混合比例调整区域内,调整每个模型的占比,使其相加=100。
④点击“声线融合启动”,稍等一会儿,就在so-vits-svc文件夹下生成一个output.pth,这个就是混合后的模型,将其重命名,并剪切到model文件夹中。
⑤回到Gradio页面,选择“推理”,模型选择选刚刚的模型,配置文件选你用来合成模型的.json文件(一般选占比最多的,不同模型的.json出来的效果有一定差别)。选择扩散模型选你用来合成的扩散模型(如果用的模型都没扩散,可不选,不同扩散效果也有差别)。
⑥全部选好后,传一段音频上去,变音试听,检查是否是想要的效果,不符合要求就继续调整(调整混合比例,更换混合模型等),直到调出想要的效果。