
此教程用于明星区同人图的制作,整个操作流程大致分为(1)收集明星素材训练lora模型(2)使用训练好的模型在Stable Diffusion中进行换脸换装(其中穿插换装换脸“底图”图1 ,图2的收集与制作),最终以达到图1.1和2.1所示的效果。
图1

图1.1

图2

图2.2

(一)模型训练(lora炼丹)
注:以下目前训练模型以及换脸换装都是基于“3D_chilloutmix.safetensors ”这一大模型,目前该模型已被下架,在学习教程前请自行寻找其他可替代的大模型(附存放位置为)
![]()
大模型模型类型为safetensors格式,大模型查询与下载网站(仅供参考):
Civitai:推荐配置(可下载鲁大师查看自己电脑的配置):
拥有Nvidia独立显卡、RTX20系以后的显卡。仅生成图片推荐8G显存(4G是最低保障配置)训练推荐大于12G(越大越好)
内存推荐16G及以上。硬盘推荐使用固态硬盘,否则你开软件要等个5-10分钟。
CPU不做太多要求。
A卡能不能用?能,但是性能损耗很大。可以在Linux系统上获得最佳效果。
详细概论请参考原作者:秋葉aaaki
1、前期准备
方法一(原生版)包含lora模型训练工程的下载,python环境的配置,请根据下方链接一步一步来
【AI绘画】保姆式LoRA模型训练教程方法二(是综合方法一后的整合版,更推荐,更方便快捷) 包含lora训练,python环境配置等,请根据链接一步步来
lora模型一键炼丹,新手更易用、老手更好用,V1.4版本视频讲解stable diffusion安装教程
点击查看教程2、Lora模型训练
方法一为最原生的Lora模型训练方法,方法二则是综合方法一后,整合流程做出的可视化整合版,方法二更适合新手,但还是建议先了解方法一中收集素材,处理素材的方法作为基础了解,两个方法结合着看会对Lora训练了解的更透彻。
方法一(原生版)
(1)训练集图片处理(最终lora的训练效果优劣,最重要因素就是素材包的准备)
素材的收集与裁切
训练素材,素材图片需高清,多角度,统一尺寸,脸部无遮挡,简单背景(建议扣除原背景并填充白色为底色)
- 面部无遮挡,越高清越好,最好能够清晰看出人物的面部走势,五官起伏,骨相
- 素材图的颜值上限,是lora效果的颜值下限,所以准备的原图越好看越好
- 素材图无水印,无黑白边,背景干净简单
- 素材分布:正面大头照55%,侧脸30%,半身照或全身照15%,最好各种表情,角度,景别丰富
- 如果原图不够高清,可以先过一遍放大算法,提升精度(在stable diffusion部分展开)
- 如果原图背景比较杂乱复杂,可以过一遍抠图软件,抠图替换纯白背景
- lora训练结果和训练集的质量直接关系最大,如果结果不好,需要每条对照自查训练集,调整素材,替换掉如照片质量差,噪点多,背景糟糕混乱等素材。
例如:下图有噪点(可能影响训练集)

下图为高清纯色背景

(2)打标签
素材图包准备完毕后,启动炼丹炉-lora(AIGC-kohya_ss),详细请参考下方链接中图像预处理部分,
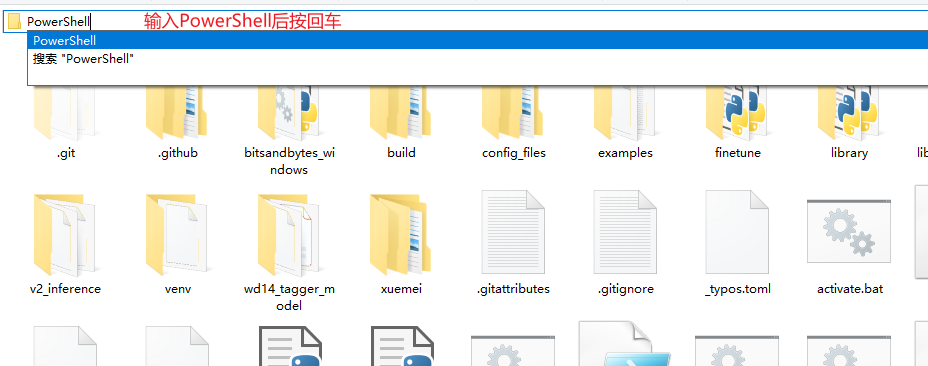
点击查看链接在该文件夹的目录处,输入PowerShell,回车(图1),打开终端管理器,在光标处直接输入:.\run.ps1 , (图2)回车。等待出现网址(图3),将该网址复制到浏览器中打开。
- 打标签为对上述训练图片单张的描述。
(图1)输入PowerShell位置
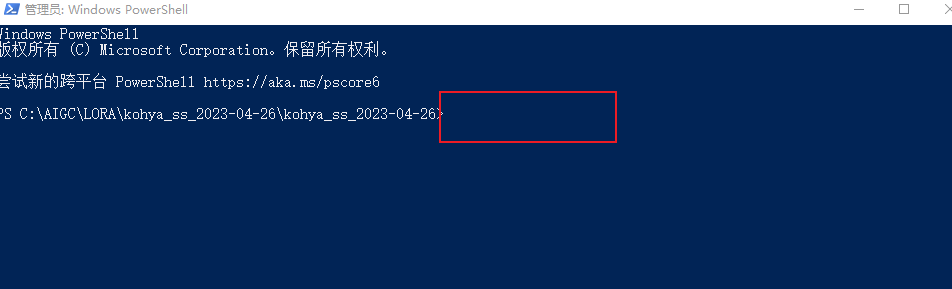
(图2)光标输入位置
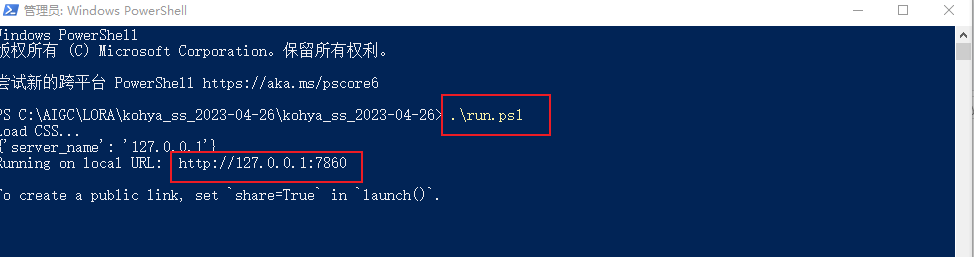
(图3)网址位置
- 打开lora界面,选择Utilities——BLIP Captioning——image folder to caption——点击右侧文件夹,上传裁剪好的训练素材文件夹,Prefix to add BLIP caption ——输入角色模型召唤词(30_lora模型名),点击下方 caption images开始标注图片,开始素材图片的标签处理。
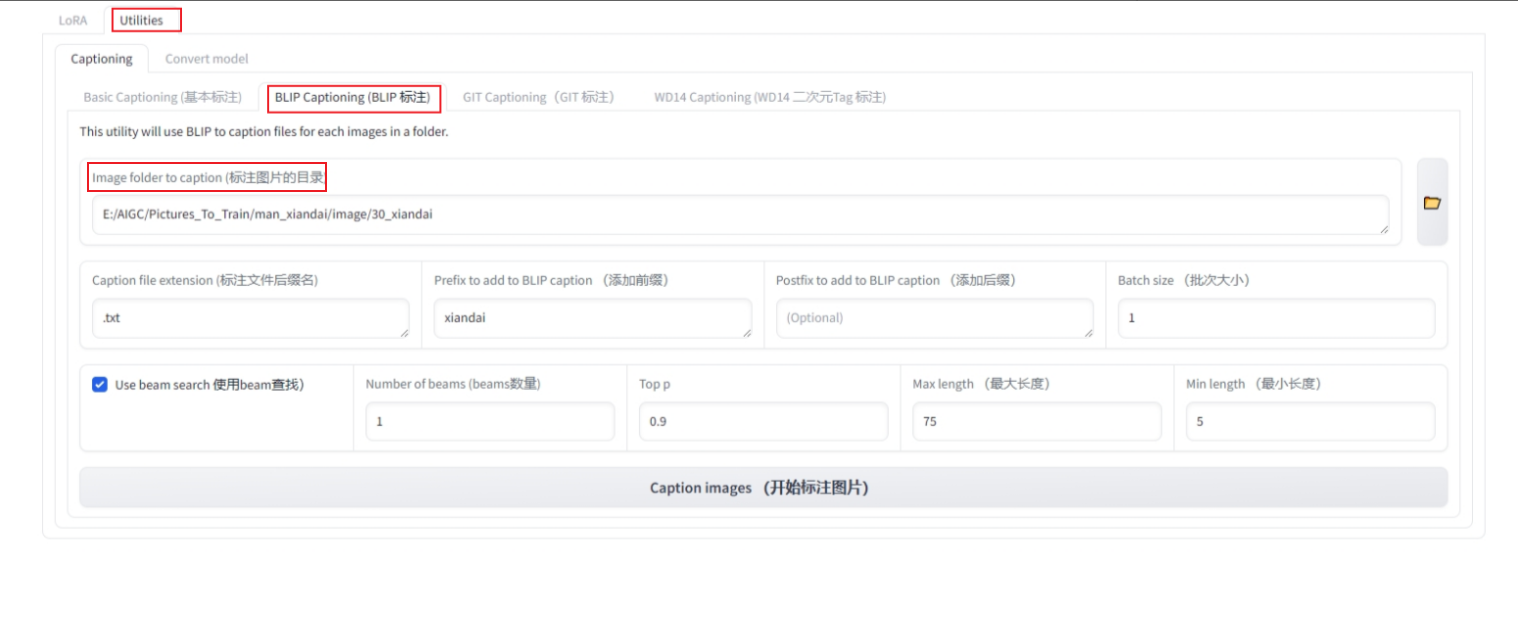
①跑完后,回到素材文件夹,检查每一张图的文字描述,手动修改增减标签。
②标签拆分越详细,可控变量越多,非角色特征类内容,都需要单独标注为标签
③标签要用词语、词组,不要用短语、句子,每个标签之间用英文字符的逗号间隔开
④通用标签范围需英文(尽量规范,统一且需用单词或词组来描述),形式一般为(仅供参考):召唤词(自己备注的30_lora名),性别(男/女),发型(长发/短发),衣服(黑色西装/灰色卫衣等...),表情(睁眼/闭眼/微笑/皱眉等....),看向何处(看着镜头/抬头看/向左/向右看等...),景别(白色背景/黑色背景等等...),面部阴影(用于比较暗的画面,脸的暗部占大多数的素材),饰品物品(戴眼镜/蓝牙耳机/项链等...),realistic,portrait,masterpiece, best quality(写实,肖像,杰作,最好的质量等一些套词)
- 参考范例:
74:lora模型名(纯英文), a man, with Black hair, Black shirt,necklace,black eyes,side face,face close-up,looking at viewer,handsome,Realistic,portrait,
33:lora模型名(纯英文), a man, with white hoodie, brown curly hair,black eyes,Smile, upper body,holding a bouquet of flowers in his hand,looking at viewer, handsome,Realistic,portrait,Motion blur

面部阴影
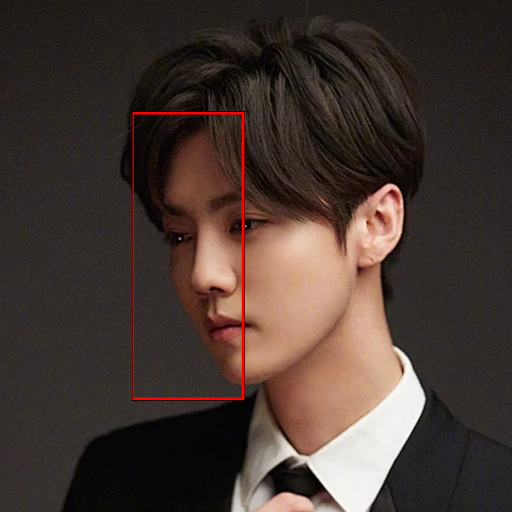
画面光线暗,人物面部有一半处于阴影
了解以上步骤后可移步方法二查看更简便操作
准备工作结束,调整参数开始lora训练
回到Lora界面,Source model 源模型——model quick pick中选择custom,预训练的模型名称下,点文件图标,上传SD中的3D_chilloutmix模型(SD\sd-webui-aki-v4\models\Stable-diffusion);
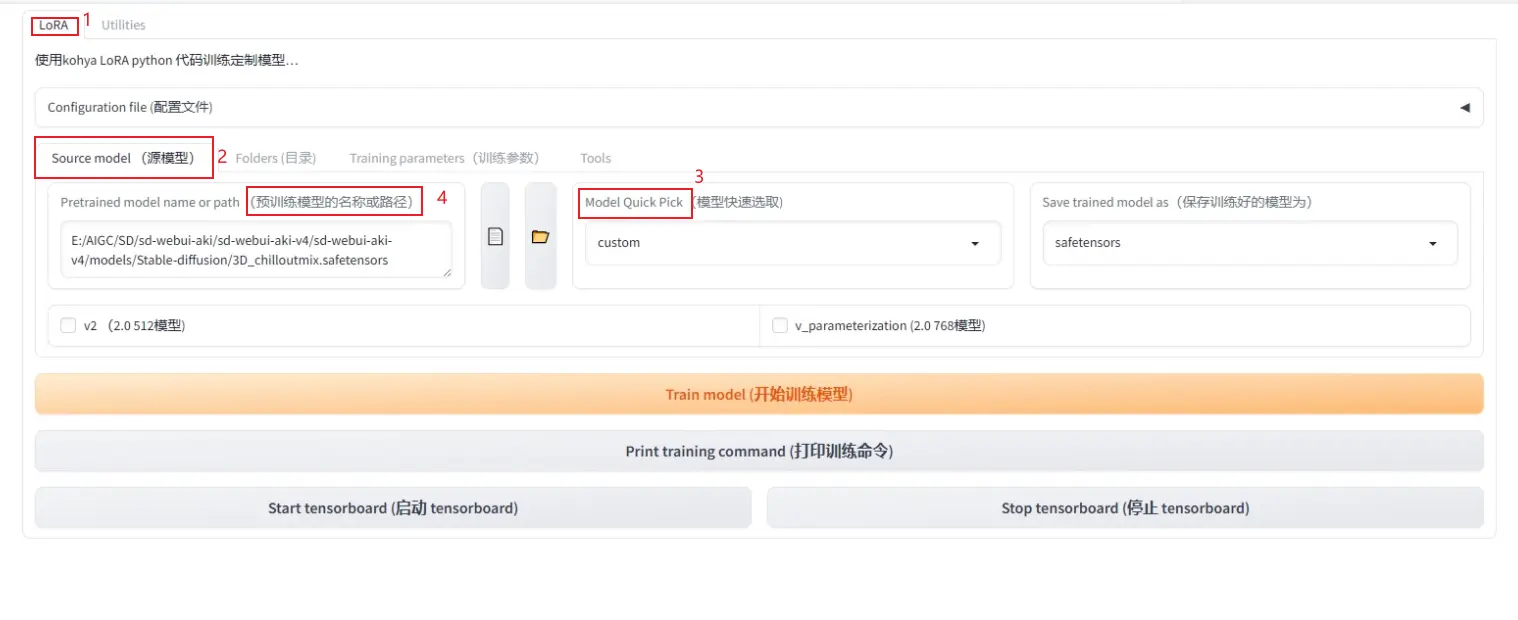
Folders——image folder 选择上传image文件夹;output选择model文件夹;logging folder选择log文件夹。Model output name——填入模型召唤词即lora模型名(纯英文)。
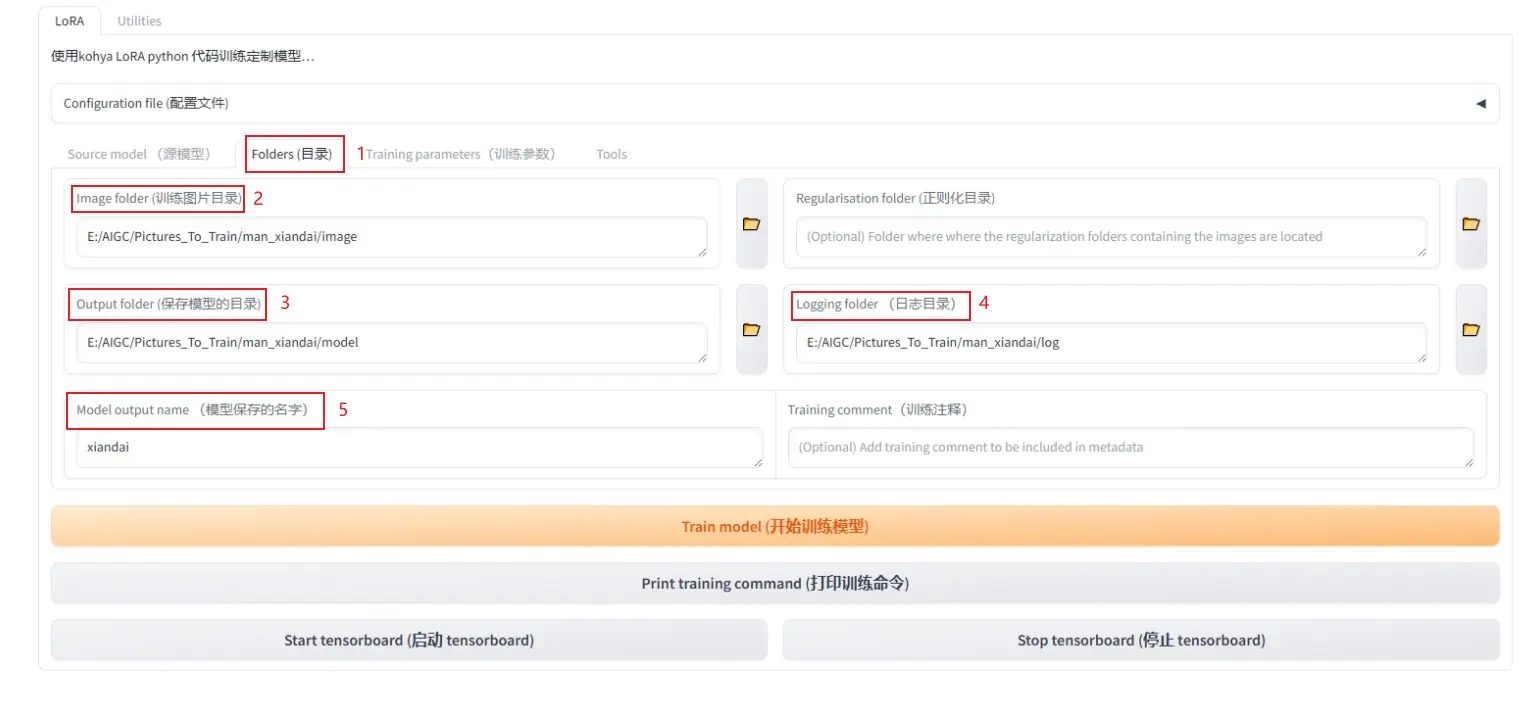
- Training paramets:
epoch-10,学习率调度器-cosine_with_restarts,学习率预热步数-0,优化器-adamW,文本编码器学习率-0.000035, UNET学习率-0.000065, network rank-160, network alpha-128, max resolution-512,768(512,512取决于训练集素材的尺寸),开始训练。
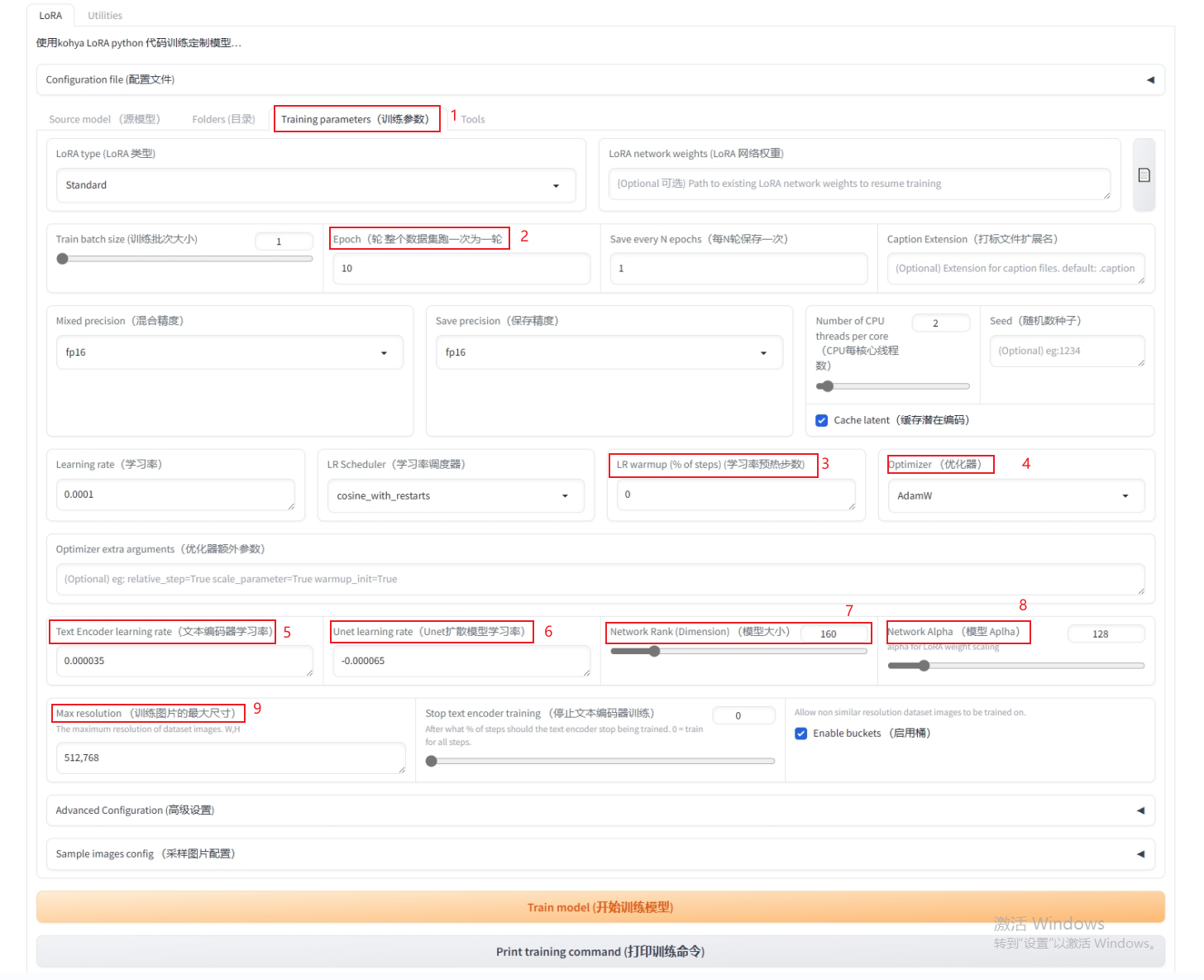
观察控制窗口,确认出现学习步数下的steps,epoch(轮次),进度条开始变化,说明成功。一个模型通常用时3-5小时,注意确认电脑设置中“关闭”自动熄屏,自动睡眠等,以防止lora训练因为上述原因中断导致模型出现问题。
方法二(整合版 适合新手)
赛博丹炉1.4训练集图片预处理一键端
点击跳转视频链接1、收集素材图片(参考方法1素材收集) 收集完成后启动赛博丹炉
2、添加,修改关键词
添加关键词
- 添加lora模型召唤词
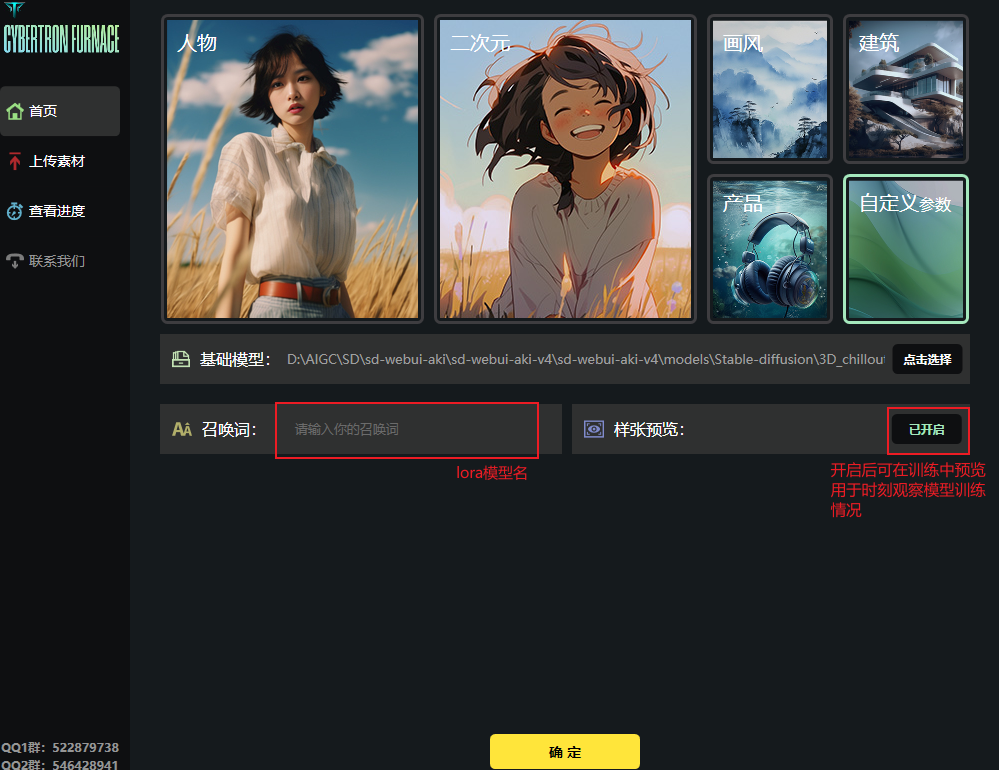
注:基础模型为SD大模型“3D_chilloutmix.safetensors ”但目前该模型已被下架,如要找大模型训练lora需去C站找替换大模型来选择(网站见教程首页)。
点击自定义参数

再点击下方确定来调整详细参数设置。
下图数值仅供参考,请以自己实际的电脑性能为准(赛博丹炉默认参数也可以)
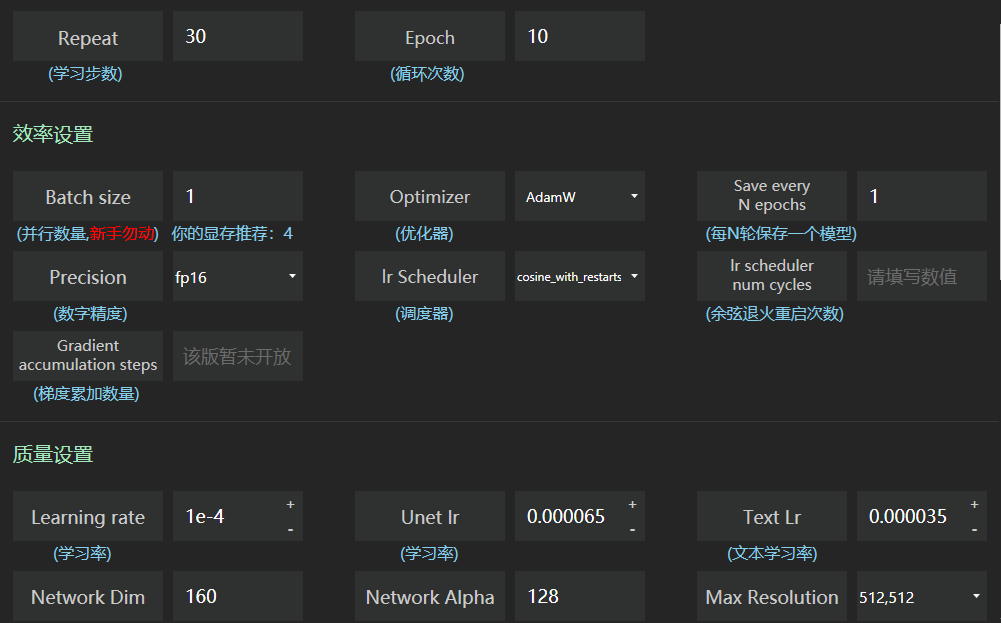
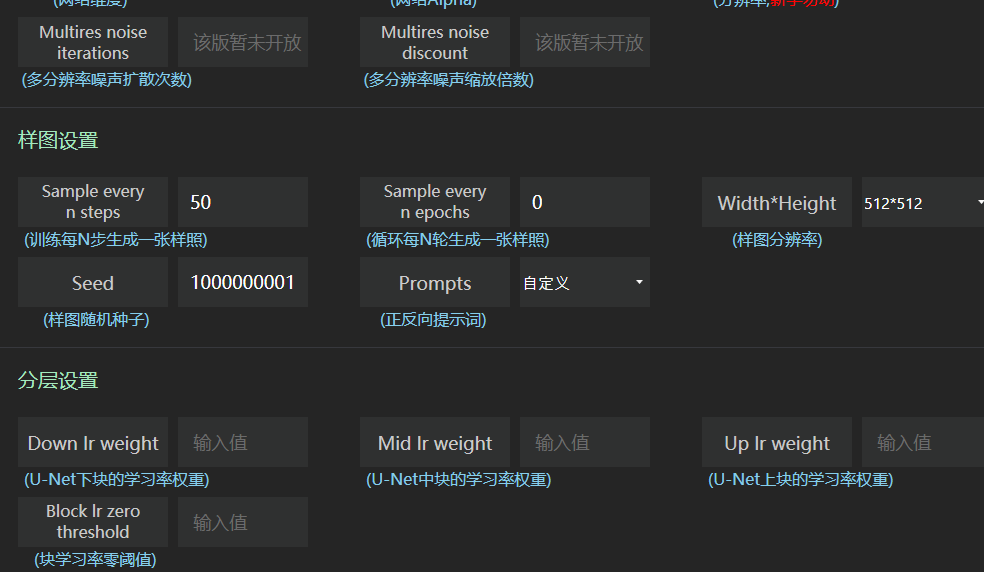
但请尤其注意设置分辨率
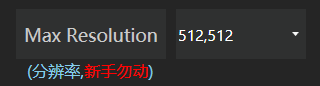
一定要与你的训练集素材尺寸一致。
- 点击上传素材,调整分辨率,模式,TAG设置为自动TAG

上图框内数值为系统打TAG的详细程度,数值越高描述词越多,越丰富(但可能会出现更多错误),一般设置为0.25就可以。
- 设置完成后点击预处理,预处理完成后可在上方“打开训练集”中查看。
修改关键词
方法1 同上文“方法一”中手动修改
方法2 点击TAG编辑

需注意(目前方法1和赛博丹炉生成的关键词全为纯英文,但目前赛博丹炉1.4有自动翻译功能,但需设置百度API,详细讲解请参考首页方法二中链接3分20秒左右)
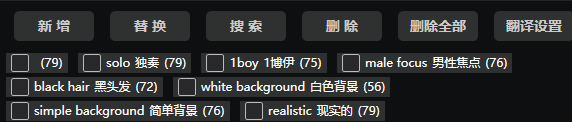
可通过选点新增,替换,删除来进行一键修改关键词(最为推荐)
3、训练lora模型
- 关键词修改好后直接点击开始训练

模型训练心得
1. 训练集质量非常影响lora模型质量
2. 图片标签(tag的描述质量)
3. 明星本身特点也是模型训练的难点
4. 训练集参考角色妆容变化大导致模型相似度低:一些明星舞台妆容与日常妆容区别较大,在训练模型时会出现相似度极低的情况,出现这种情况时,应该选择同时期且同类型素材重新进行模型训练。

点击下方链接跳转(二)stable diffusion安装和使用教程
[AI教学]明星区同人模型+换装教程(二)stable